Desde carros autónomos, cámaras de vigilancia, Google Photos y demás, hemos ido aprendiendo a confiar en la Inteligencia Artificial. Sin embargo, los sistemas de ‘visión’ de las máquinas no son completamente infalibles. Así lo demostró un grupo de estudiantes del MIT. Los investigadores lograron ‘engañar’ a la AI de Google para que confundiera la imagen de una tortuga por una de un rifle, según informó The Verge.

Se trata de una figura de tortuga impresa en 3D. Este tipo de imágenes se conoce con el nombre de ‘imagen adversaria’. En el mundo de la AI, son fotos diseñadas de forma que puedan engañar a los software de visión de máquinas, porque incorporar patrones especiales que confunden a los sistemas de AI. Es como una ilusión óptica pero para los computadores. Son patrones de diseño que engañan a las máquinas, pero al ojo humano no se pueden notar.
Este sistema de engaño podría tener muchas consecuencias en el futuro, cuando usemos de forma más masiva los sistemas de AI. Es por eso que los investigadores de AI están estudiando formas para proteger sus máquinas de estas confusiones. Aunque muchas de sus técnicas son efectivas, puede ser muy fácil pasar por encima de las protecciones. Pero el descubrimiento de la tortuga resulta importante en esta área porque demuestra cómo funcionan estos ‘ataques’ en el mundo del 3D.
¿Por qué es importante?
En términos concretos, esto significa que es posible construir un letrero en la calle que para los humanos parezca un aviso convencional, pero que para el sistema AI de un carro autónomo parezca un transeúnte en la vía. Así lo explicó el comunicado de Labsix, el grupo de estudiantes del MIT.
Labsix nombró a su método de confusión ‘Expectation Over Transformation’ (puedes leer el artículo académico aquí). En este demostraron que pueden hacer que una tortuga se vea como un rifle, o que una bola de baseball parezca una taza de café, y varios otros ejemplos.
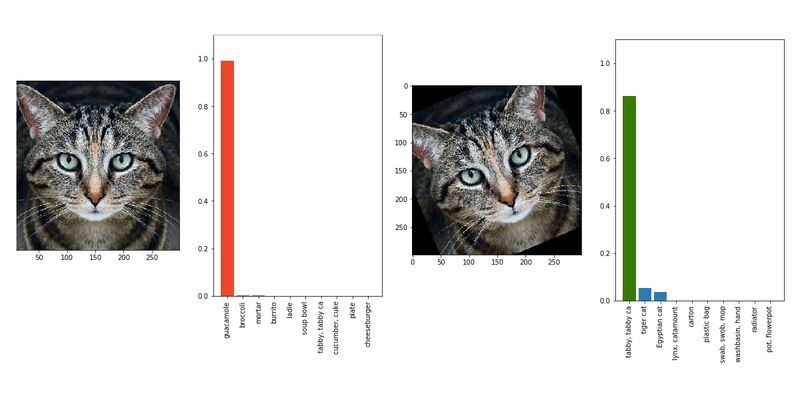
El grupo probó su ataque sobre un sistema de clasificación de imágenes de Google llamado Inception-v3. La compañía tiene esa máquina disponible para que investigadores la usen a su gusto. Aunque no es un sistema comercial, no está lejos de serlo, dice el medio. Además, a pesar de que el ataque no se ha probado en ningún otro software de visión, hasta el momento no existe ninguna protección para imágenes adversariales.

Google decidió no comentar a The Verge sobre la investigación de los estudiantes, pero el vocero compartió una lista de artículos y estudios que describe formas de protegerse de ataques de este tipo, realizados por investigadores de la compañía.
Es preocupante, pero no tanto
El sistema de los estudiantes también tiene sus límites. Por ejemplo, el equipo dice que si ataque funciona desde todos los ángulos, pero no es del todo cierto, nota el medio. En su propio video de demostración, se muestra que el engaño funciona desde casi todos los ángulos, no todos.
Además, Labsix debió haber tenido acceso al algoritmo de visión de Google para poder identificar sus debilidades. Esta es una barrera importante, es decir, no cualquier persona que quiera podría usar este método contra sistemas de visión comerciales.
Es por eso que podemos decir que los ataques adversariales no son, por el momento, una amenaza para el público en general. Son efectivos, pero en circunstancias limitadas. Aunque la visión de máquinas se está esparciendo en cada vez más aplicaciones de la vida cotidiana, aún no somos tan dependientes como para que en serio nos preocupen este tipo de ataques. No obstante, esta demostración es una prueba de lo frágiles que pueden ser los sistemas de AI. Lo que es cierto es que si no se comienzan a arreglar este tipo de vulnerabilidades, sí serán un problema más adelante.
Imágenes: capturas de pantalla y labsix.